
先日の記事でご紹介した通り、ChatGPTにフォーマットを指定して出力させることにより、文章以外の制作を行うことが出来ます。
この記事ではChatGPTからドキュメントやスライド等を出力させる方法についてご紹介します!
システム方式
流れとしては以下のようなものとなります。
- OpenAIに対してMarkdown形式出力するようにリクエストを行う
- Markdown形式のファイルをWord・PDF・パワポ形式に変換
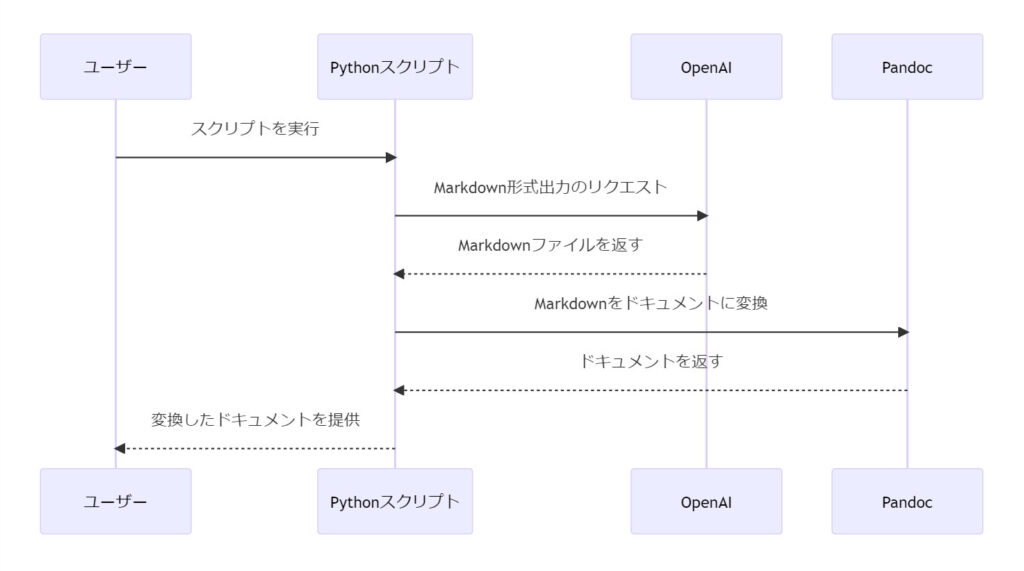
上記のPythonスクリプト部分さえ用意すれば、自動でたくさんのドキュメントを作ることが可能になる……という訳です。
なお、今回紹介するスクリプトはあくまでサンプルなので、環境やAIのレスポンス結果によってはエラーとなる可能性があります。
(特に、日本語で指示を出すとエラーがでたりします……LaTeXの文字コードによるエラーです)
下準備~
さっそく作り方をご紹介したいところですが、まずは下準備からです。
まずはopenaiのライブラリと、ChatGPTのAPIキーが必要になります。
初めて使う方は『pythonで実行する前の準備』、『APIキーの取得方法』を参照してください。
また、ドキュメントへの変換等は『pandoc』というオープンソースのコンバータを使用します。
これもインストールしましょう。
pip install pypandoc更に、pandocを利用するためには『Tex Live』も必要になります。
このページから『install-tl-windows.exe』等をクリックしてダウンロードしてください。
解答後、更にインストーラを動かす必要があります……正直大きいので1時間半ほど放置できる時にやるのがおすすめです。
では早速コードを書いていきます。
最初にいつものインポートとAPIキーの入力です。
import openai
openai.api_key = os.environ.get('OPENAI_API_KEY')OpenAIにMarkdown形式でリクエスト
以下のようなコードで、ChatGPTにリクエストを送ります。
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "Markdown output ai system."},
{"role": "user", "content": "<リクエストするメッセージ>"},
],
)【model】は執筆時点で利用することの出来る『gpt-3.5-turbo』を指定します。
【role】の指定部分ですが、”system”はAIに対して『何の役割を持つAIなのか』指示する箇所になります。
ここでは『Markdown output ai system.』(マークダウンを出力するAIシステム)であることを指示しています。
【role】の”user”部分は、実際の指示を出す部分です。
ここに出力させたいドキュメントの詳細を記入します。
例えば
{"role": "user", "content": "Please output the outline of the company ABC Co., Ltd."},といった書き方をします。
実用的にするなら、もっと詳細を書き込んだほうが良いかもしれません。
Markdown形式をPDF形式に変換
ここからは出力されたMarkdown形式のテキストを、それぞれのドキュメントに変換する処理へ移ります。
import pypandoc
with open('temp.md', 'w') as f:
f.write(response.choices[0].message.content)
pypandoc.convert_file('temp.md',
'pdf',
outputfile='result.pdf')最初に少し書きましたが、pandoc(Markdown形式をPDFに変換するツール)のPython版ライブラリのpypandocを使用します。
OpenAIからのレスポンスをMarkdown形式に変換し、その後「result.pdf」というファイルに変換する処理です。
‘pdf’部分を’docx’にすればwordファイル、’pptx’でPowerPointファイルになります。
サンプルコードと出力結果
import openai
openai.api_key = os.environ.get('OPENAI_API_KEY')
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "Markdown output ai system."},
{"role": "user", "content": "Please output the outline of the company ABC Co., Ltd."},
],
)
import pypandoc
with open('temp.md', 'w') as f:
f.write(response.choices[0].message.content)
pypandoc.convert_file('temp.md',
'pdf',
outputfile='result.pdf')

OpenAIのレスポンスが正しく返ってこない場合は?

ChatGPTは対話型のAIなので、『Markdown形式で返答して』と述べても、テキストを混ぜて返すことがあります。
そのようなケースでは、以下のような対策を取るとうまくいくかもしれません。
{“role”: “assistant”, “content”: “<アシスタントメッセージ>”}を利用
『”role”: “assistant”』は、『前回のやり取りを参照させる』『望ましい動作の例を提示する』ための指示部分です。
なので、ここに理想となる返答形式を予め記述しておくことで、次に質問する際もそれに沿った書式で返答を行ってくれます。
書き方としては以下のような形になります。
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "Markdown output ai system."},
{"role": "user", "content": "質問例を書く"},
{"role": "assistant", "content": "回答例を書く"},
{"role": "user", "content": "本番の質問をする"},
],
)
LangChainを利用
『LangChain』とは、ChatGPT等の大規模言語モデルを使いやすくしてくれるフレームワークです。
色々便利な機能が詰め込まれているのですが、その中の一つ『Output Parsers』は、出力された情報を解析したり、構造化データを抽出したり、といった用途に向けて設計されています。
今回のようなマークダウンにとどまらず、色々な構造化データを取り扱うことが出来るので、是非活用してみましょう。
(近々、このLangChainについても解説します)
Fine-tuningを利用
そして最も強力な手段が『Fine-tuning』です。
ChatGPTが望む返答を返してくれないのであれば、望む返答しか返さないようにChatGPT自体を調整しよう……そんなことも可能なのです。
ただし、これにはいくつかのハードルがあります。
まずChatGPTをトレーニングするための学習用データが必要です。少量のデータでも『Fine-tuning』を行うこと自体は可能ですが、望みどおりのAIになるかはわかりません。
更に『Fine-tuning』を行うには、時間とお金が掛かります。
限定的な用途であれば、少ないデータセットでもトレーニングが完了し、時間・料金ともにあまり多くない負担で済むかもしれません。
しかし、本格的にトレーニングを行いたい場合は、大量のデータセットを読ませる必要があります。
その場合は、決して安くない費用・想像以上の料金が掛かるでしょう。
更に『うまくトレーニングできたか』を検証するための作業も必要です。
これにも作業時間やAPI料金が発生しますし、もしうまく行ってなければ追加のトレーニングを行う必要があります。
『Fine-tuning』は決して簡単な作業ではありません。ただし、もしうまく行けば最高のAIがあなたを補助してくれることになります。
もし『そのコストを支払っても良い』と思う場合は、ぜひチャレンジしてみてください!
