今回は少し趣向を変えて、OpenAIのAPIを使った開発手法をご紹介したいと思います。
作ってみるのは『ベクトル検索』です。
『ベクトル検索』とはデータをベクトル(数値の配列)に変換し、そのベクトルの間の距離や類似性に基づいて検索を行う技術です。
例えば太宰治の小説をベクトルデータに変換し、データベースに入れ込むと下記のような形になります。
従来のキーワード検索とは異なり、ベクトル検索はデータの意味や文脈を理解するため、より関連性の高い結果を返すことができます。
本来ベクトル検索は本来多大な計算リソースが必要な技術でしたが、AIが使える今となっては違います。大規模言語モデルを使えば、簡単なコードでベクトル検索を実装することが可能です。
今回は『OpenAI Embeddings API』『Supabase Vector Database』『Next.js』を使い、太宰治の小説をベクトル検索できるアプリを作成します。

Supabaseのデータベースに実際に格納するベクトルデータは、このような形になります。

OpenAIのtext-embeddingモデル(`text-embedding-ada-002`)を利用することで、このベクトルを作成し、キーワード検索とは違う関連度や特徴をもとにした検索を行うことができるのです。
それでは実際に作成方法を説明します。
Supabaseの設定
※Supabaseのプロジェクトの作成は終わっている前提です。
vectorの有効化
まずSupabaseのダッシュボードにあるDatabaseのExtensionsから、`vector`を検索し有効にします。
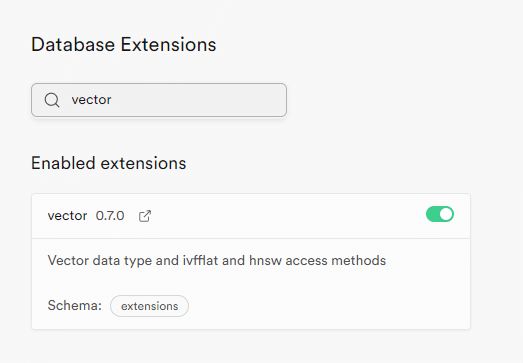
これはSupabaseにVector型を追加するための拡張機能です。
テーブル作成
vector拡張の追加が終わったらSQL Editorで下記のSQLを実行して下さい。
CREATE TABLE novels (
id SERIAL PRIMARY KEY,
title VARCHAR(255),
publication_date TEXT,
full_text TEXT,
embedding VECTOR(1536)
);これでnovelsというテーブルが作成されます。
※ポリシーは作成されないため、自分で設定してください。
小説検索用の関数作成
今回検索機能を作るにあたり、検索ワードと小説の類似度を元に検索を行うデータベース関数を作成します。
同じくSQL Editorで下記を実行してください。
CREATE OR REPLACE FUNCTION match_novels(
query_embedding VECTOR(1536),
match_count INT
) RETURNS TABLE (
id INT,
title VARCHAR,
publication_date TEXT,
full_text TEXT,
similarity FLOAT
) AS $$
BEGIN
RETURN QUERY
SELECT n.id, n.title, n.publication_date, n.full_text, 1 - (n.embedding <=> query_embedding) AS similarity
FROM novels n
ORDER BY n.embedding <=> query_embedding
LIMIT match_count;
END;
$$ LANGUAGE plpgsql;Next.jsの実装
ここからはNext.js側の実装に移ります。
今回は今までと違ってSupabase上でログインをするわけではないため、後からSupabaseを導入しようと思います。
まずはシンプルにNext.jsのプロジェクトを作成します。
npx create-next-app my-embedding-search次にプロジェクト直下で必要なライブラリをインストールします。
npm install @langchain/openai @supabase/supabase-js dotenv gray-matter puppeteer今回のプロジェクトでは
- スクレイピングでデータを集める
- 集めたデータをSupabaseのデータベースに追加
- Supabaseのデータベースをもとに検索
という形で制作を進めるため、まずはスクレイピングと、”Supabaseのデータベースに追加するためのNext.jsのアプリ外の機能”を作成していきます。
環境変数の設定
`.env`ファイルを作成し、下記のように情報を入力しましょう。
NEXT_PUBLIC_SUPABASE_URL={SupabaseプロジェクトのURL}
NEXT_PUBLIC_SUPABASE_ANON_KEY={Supabaseプロジェクトのキー}
OPENAI_KEY={OpenAI APIキー}このうち、OpenAIのキーに関しては下記からログインして自分で作成してください。
※ユーザ登録から時間が経ち、トライアルで利用できない場合は課金の必要があるため気を付けてください。
https://openai.com/index/openai-api/
スクレイピング
プロジェクトの直下に`scraping.js`を作成します。
中身は下記のような形です。
import puppeteer from "puppeteer";
import fs from 'fs';
import path from 'path';
import { fileURLToPath } from 'url';
const __filename = fileURLToPath(import.meta.url);
const __dirname = path.dirname(__filename);
const directoryPath = path.join(__dirname, 'docs');
async function clearDirectory() {
if (fs.existsSync(directoryPath)) {
fs.readdirSync(directoryPath).forEach((file) => {
const filePath = path.join(directoryPath, file);
if (fs.lstatSync(filePath).isDirectory()) {
clearDirectory(filePath);
} else {
fs.unlinkSync(filePath);
}
});
} else {
fs.mkdirSync(directoryPath);
}
}
async function saveNovelToMDX(novelInfo, index) {
const { title, publicationDate, content } = novelInfo;
const mdxContent = `---
title: "${title}"
date: "${publicationDate}"
---
${content}
`;
const fileName = `novel-${index + 1}.mdx`; // 連番をファイル名に使用
const filePath = path.join(__dirname, 'docs', fileName);
fs.writeFileSync(filePath, mdxContent);
console.log(`Novel saved to ${filePath}`);
}
(async () => {
await clearDirectory()
const url = 'https://www.aozora.gr.jp/index_pages/person35.html';
const browser = await puppeteer.launch({ headless: "new" });
const page = await browser.newPage();
await page.goto(url);
const linkSelector = 'body > ol:nth-of-type(1) > li > a:nth-of-type(1)';
let urlList = await page.$$eval(linkSelector, nodes => nodes.map(el => el.href));
for (let i = 0; i < urlList.length; i++) {
// 小説の基本情報ページ
await page.goto(urlList[i]);
const titleSelector = 'body > table[summary=タイトルデータ] > tbody > tr:nth-of-type(1) > td:nth-of-type(2) > font';
await page.waitForSelector(titleSelector);
const title = await page.$eval(titleSelector, el => el.innerHTML);
console.log("title: " + title);
// 清貧譚の英訳版は無視する
if (title === "『清貧譚』英訳版 A Tale of Honorable Poverty") continue;
let publicationDate = "日付データなし";
const publication_date_header = await page.$eval('body > table[summary=作品データ] > tbody > tr:nth-of-type(2) > td.header', el => el.innerHTML);
if (publication_date_header === "初出:") {
const tmp_publicationDate = await page.$eval('body > table[summary=作品データ] > tbody > tr:nth-of-type(2) > td:nth-of-type(2)', el => el.innerHTML);
publicationDate = tmp_publicationDate.replace(/<([^'">]|"[^"]*"|'[^']*')*>/g, '');
}
// 本文ページ
const main_textSelector = "body > div.main_text";
await page.click('body > table[summary=ダウンロードデータ] > tbody > tr:last-of-type > td:nth-of-type(3) > a');
await page.waitForSelector(main_textSelector);
const tmp_main_text = await page.$eval(main_textSelector, el => el.innerHTML);
const main_text = tmp_main_text.replace(/<([^'">]|"[^"]*"|'[^']*')*>/g, '');
// 小説情報をMDXファイルに保存
const novelInfo = {
title,
publicationDate,
content: main_text
};
await saveNovelToMDX(novelInfo, i);
// 小説家ページに戻る
await page.goto(url);
await page.waitForSelector(linkSelector);
}
await browser.close();
})();細かい説明は割愛しますが、下記のページから必要情報を取得してくる処理になっています。
https://www.aozora.gr.jp/index_pages/person35.html
取得したファイルはdocsフォルダ直下に下記のような形で書き出されます。
---
title: "タイトル"
date: "刊行日時"
---
本文作成が終わったら、下記コマンドで実行しましょう
node scraping.js添付画像のようにdocsフォルダにmdxファイルが並べばOKです。
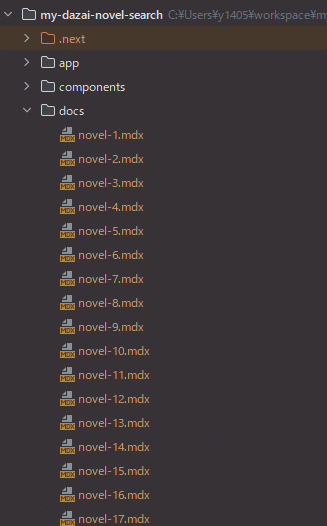
Supabaseにmdxファイルの内容を追加
次にmdxファイルをまとめてSupabaseに行として追加する処理を行います。
こちらは`import-novels.js`として作成してください。
import { createClient } from '@supabase/supabase-js';
import { OpenAIEmbeddings } from "@langchain/openai";
import fs from 'fs';
import path from 'path';
import matter from 'gray-matter';
import "dotenv/config.js";
const supabase = createClient(process.env.NEXT_PUBLIC_SUPABASE_URL, process.env.NEXT_PUBLIC_SUPABASE_ANON_KEY);
const MAX_TOKENS = 6000; // 安全な範囲で分割、本来はtiktokenなどで文字数をトークン数に変換する必要があるがシンプルに実装したいので一旦やっていない。
function splitText(text, maxTokens) {
const chunks = [];
let startIndex = 0;
while (startIndex < text.length) {
let endIndex = Math.min(startIndex + maxTokens, text.length);
chunks.push(text.slice(startIndex, endIndex));
startIndex = endIndex;
}
return chunks;
}
async function generateAndStoreEmbeddings(novels) {
const embeddings = new OpenAIEmbeddings({
openAIApiKey: process.env.OPENAI_KEY,
model: 'text-embedding-ada-002' // OpenAIの1536次元の埋め込みを生成するモデル
});
for (const novel of novels) {
const chunks = splitText(novel.full_text, MAX_TOKENS);
for (const chunk of chunks) {
const embedding = (await embeddings.embedDocuments([chunk]))[0];
const { error } = await supabase
.from('novels')
.insert({
title: novel.title,
publication_date: novel.publication_date,
full_text: chunk,
embedding
});
if (error) {
console.error('Error inserting novel:', error);
}
}
}
}
async function readMDXFilesAndImport() {
const novels = [];
const files = fs.readdirSync('docs');
for (const file of files) {
const filePath = path.join('docs', file);
const fileContents = fs.readFileSync(filePath, 'utf8');
const { data, content } = matter(fileContents);
novels.push({
title: data.title,
publication_date: data.date,
full_text: content
});
}
await generateAndStoreEmbeddings(novels);
}
readMDXFilesAndImport();今回使うモデルにおけるトークン(OpenAIにおける文字のカウント単位。文字数とは違う)の長さが小説一つだと制限を超えることがあるので、細かい単位に分けています。
本来は文字数ではなくトークンの長さを元に切り出すのが良いのですが、今回はシンプルにざっくりこのぐらいならOKだろうという文字数で対応しています。
下記のコマンドで実行してみましょう。
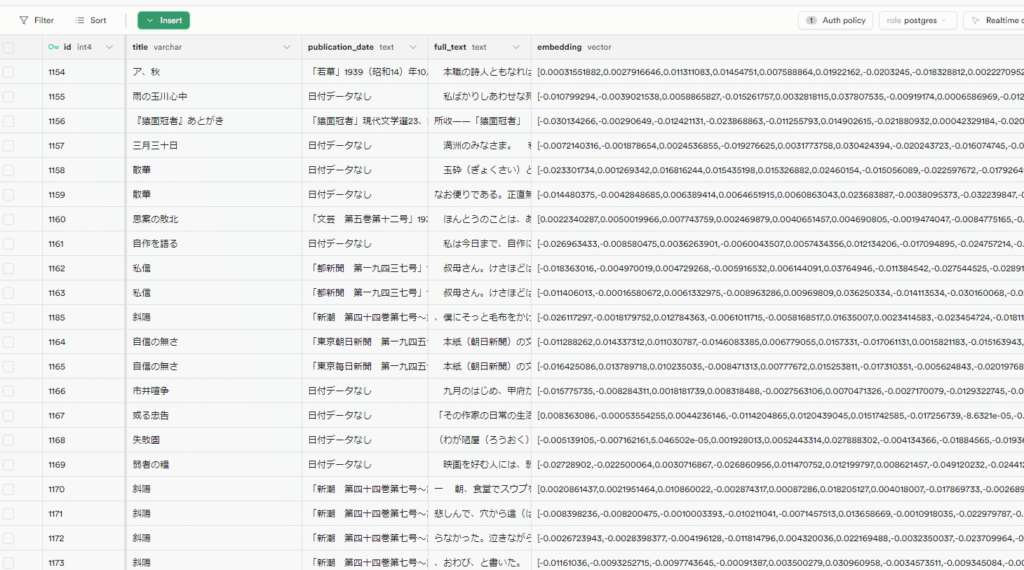
node import-novels.js実行完了まで時間がかかりますが、終わるとSupabaseのnovelsテーブルの内容が添付画像のような形になります。
ここまで終わったらアプリの実装に移ります。
検索アプリ実装
まずはcomponentディレクトリを作成しつつ、appディレクトリとcomponentディレクトリの中身を添付画像のような形にしましょう。
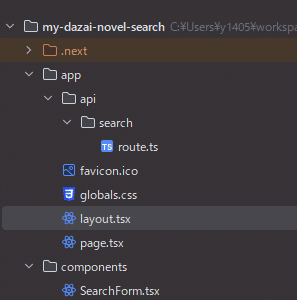
このうちglobals.cssの中身は一旦利用しないため、全て削除しておいてください。
各ファイル作成をしていきます。
app/page.tsx
こちらはコンポーネントの`SearchForm.tsx`を読み込むだけにしています。
import {SearchForm} from "@/components/SearchForm";
export default function Home() {
return (
<div>
<h1>太宰治の小説検索</h1>
<SearchForm />
</div>
);
}components/SearchForm.tsx
実際に検索と検索した小説の表示処理を行うコンポーネントです。
検索用のapiを叩くのもこちらになります。
"use client"
import { useState } from 'react';
export const SearchForm = () => {
const [query, setQuery] = useState('');
const [results, setResults] = useState<any[]>([]);
const searchNovels = async () => {
const response = await fetch(`/api/search?query=${query}`);
if (response.ok) {
const data = await response.json();
console.log(data.data);
const uniqueResults = data.data.filter((novel: any, index: number, self: any) =>
index === self.findIndex((n: any) => n.title === novel.title)
);
setResults(uniqueResults);
}
};
return (
<div>
<input type="text" value={query} onChange={(e) => setQuery(e.target.value)} />
<button onClick={searchNovels}>検索</button>
<ul>
{results.map((novel) => (
<li key={novel.id}>
<h2>{novel.title}</h2>
<p><em>Publication Date: {novel.publication_date}</em></p>
</li>
))}
</ul>
</div>
);
}app/api/search/route.ts
こちらが検索用のAPIです。
Supabase上に作成したmatch_novels関数を実行して、結果を取得してSearchFormに渡しています。
import { createClient } from '@supabase/supabase-js';
import { OpenAIEmbeddings } from '@langchain/openai';
import {NextResponse} from "next/server";
const supabase = createClient(process.env.NEXT_PUBLIC_SUPABASE_URL!, process.env.NEXT_PUBLIC_SUPABASE_ANON_KEY!);
export async function GET(req: Request) {
const url = new URL(req.url!);
const query = url.searchParams.get("query");
if (query == null) {
return NextResponse.json({ error: "query not found" }, { status: 500 })
}
const embeddings = new OpenAIEmbeddings({
openAIApiKey: process.env.OPENAI_KEY,
model: 'text-embedding-ada-002' // OpenAIの1536次元の埋め込みを生成するモデル
});
const queryEmbedding = await embeddings.embedDocuments([query]);
const { data, error } = await supabase.rpc('match_novels', {
query_embedding: queryEmbedding[0],
match_count: 5 // 上位5件の類似度を取得
});
if (error) {
console.log(error.message);
return NextResponse.json({ error: error.message }, { status: 500 })
}
return NextResponse.json({ data }, { status: 200 })
}これで作成は完了です。
実装の確認
npm run devでアプリを立ち上げます。

適当にワードを入れて検索してみると下に検索結果が表示されます。

コンソールに検索した小説の情報が格納されているので、何に引っかかって検索されたのかがなんとなくわかるかと思います。

別のワードで検索すると別の小説がまた出てきます。
(お酒と入力したら酒関係のタイトルが羅列されたので明確ですね)

これで小説ベクトル検索アプリが完成しました!
その他参考資料など
弊社では『マッチングワン』という『低コスト・短期にマッチングサービスを構築できる』サービスを展開しており、今回ご紹介するコードは、その『マッチングワン』でも使われているコードとなります。
本記事で紹介したようなプロダクトを開発されたい場合は、是非お問い合わせください。
またTodoONada株式会社では、この記事で紹介した以外にも、Supabase・Next.jsを使ったアプリの作成方法についてご紹介しています。
下記記事にて一覧を見ることができますので、ぜひこちらもご覧ください!
- Next.js + SupabaseでTodoアプリ作成 CRUDの基本を学ぼう
- FirebaseとSupabaseの機能、料金、セキュリティ、AI観点などを含めて徹底比較
- Next.js とSupabaseで求人マッチングアプリを作る①
- 素早くアプリを作りたい! Vercel+Supabaseでプロジェクト開発
- Supabaseの機能一覧・解説 オープンソースのFirebase代替mBaaS
- Supabase CLIコマンド一覧
- Supabase RealtimeのBroadcast, Presenceを利用したキャンバス共有アプリを作る
- Supabaseのローカル開発環境を構築して開発体験を向上させつつ料金も節約
- Next.js + Supabaseでリアルタイムチャットを作ろう
- Next.js + Supabaseでソーシャルログインを実装する方法
- Next.js+Supabaseで認証機能を実装しよう【コード付き完全ガイド】
- Supabase + Next.jsで画像投稿アプリを最適化する(画像圧縮、ファイルサイズ制限、ファイルのアップロード数制限)
- OpenAI Embeddings API+ Supabase Vector Database + Next.jsでベクトル検索を実装する
- Supabase + AWS CognitoでAmplifyを利用せずサードパーティ認証する
- Supabaseでデータ更新があった時にSlack通知を送る
- Supabase Branchingでプレビュー環境を手に入れて開発体験を向上する
- Next.js + SupabaseでGraphQLを利用する方法
- SupabaseのEdge FunctionsとSendGridでメールを一斉送信する
- Supabaseで匿名認証とアカウントの本登録への昇格の方法
- Next.js + SupabaseでStorageを利用した画像投稿アプリ作成
- Next.js + SupabaseでRLSを利用して安全なアプリを作ろう。
- Next.js + SupabaseでAuth + Storageのストレージサービスを作る方法
- Next.jsとSupabaseで認証機能ありのリアルタイムチャットを作成する。
- Next.jsとSupabaseで認証つきチャットアプリを作成する(SNS風UI)
- Next.js + SupabaseでSMS認証を作成する方法
- Next.jsとSupabaseで全文検索を実装する方法
- Next.jsとSupabaseで作成したチャットアプリにお知らせ機能を実装する
- Nextjs + SupabaseでSupabaseのStorage Image Transformationsを利用する方法
- Supabase vs Neonの比較。機能や料金、セキュリティ、AIを徹底比較
- Supabaseのセルフホスティングをできるだけ安く行う方法
- Supabase + Cognitoの連携で外部連携を試す
- Supabase CLIのTesting機能を利用する
- Supabaseを利用する際に設定しておきたい項目
お問合せ&各種リンク
- お問合せ:GoogleForm
- ホームページ:https://libproc.com
- 運営会社:TodoONada株式会社
- Twitter:https://twitter.com/Todoonada_corp
- Instagram:https://www.instagram.com/todoonada_corp/
- Youtube:https://www.youtube.com/@todoonada_corp/
- Tiktok:https://www.tiktok.com/@todoonada_corp
presented by

